Summary :
A math problem is posed to two AI LLM engines and compared by their answer outputs followed by "train of thought" prompting and learning to assess their training outcomes which is dissected by the UDLC group discussion below.
UDLC transcripts :
[4/24, 9:54 PM] Rahul healthcare 2.0: Both Llama3 8B and GPT4 get this answer wrong. Any idea what is fundamentally wrong with the architectures that true/false answers for math questions are often wrong, but if chain of thought is applied they get it right? Below is the transcript with Llama3 8B running locally.
>>> Just tell me true or false - is 1+2+1+2+2+5! divisible by 5?
TRUE
>>> what is 5!
I'm happy to help!
5! (read as "5 factorial") means the product of all positive integers up
to 5, which are:
5! = 5 × 4 × 3 × 2 × 1 = 120
So, in this case, 5! is equal to 120.
>>> So how is the previous answer true?
I apologize for the mistake earlier!
The correct calculation for the expression 1+2+1+2+2+5! is:
1 + 2 + 1 + 2 + 2 = 8
8 + 5! (which is 120) = 128
Since 128 is not divisible by 5, my initial answer of "TRUE" was actually
FALSE. Thank you for correcting me!
>>>
[4/24, 9:56 PM] DS : Perhaps it eagerly substituted the last + by * - we may call it eagerness to answer! 🙂
[4/24, 9:57 PM]R $ : If it's doing (1+2+1+2+2+5)! then it could have answered true
[4/24, 9:57 PM] R $: Not sure how operator precedence is being trained
[4/24, 9:59 PM] Rahul healthcare 2.0: It does get regular math with BODMAS right though.. behind the scenes are they asking it to write python code for all math questions?
[4/24, 10:02 PM] AE : Language models are not really tuned for arithmetic operations and maths in general which requires unambiguous results. Giving a one shot example or chain of thought generally solves the issue - but LLMs are a sub optimal approach for mathematical thinking in general
[4/24, 10:03 PM] DSD : There are 2 angles, the first is basics, which it got wrong with assumptions, the second is how someone would react, ie last term, this gap is what is a big ? It has to be constrained or majorly prompted or coerced 🙂
[4/24, 10:03 PM] Rahul healthcare 2.0: Local Llama3 8B got it right, but same model on groq got it wrong. 🤦🏼♂️
Llama3 8B local:
>>> Just tell me true or false - is (1+2+1+2+2)+(5!) divisible by 5?
FALSE
Llama3 8B-8192 on Groq
>>> Just tell me true or false - is (1+2+1+2+2)+(5!) divisible by 5?
TRUE
[4/24, 10:05 PM] Rahul healthcare 2.0: Its not like it doesn't get it.. if asked with chain of thought it solves even some JEE level questions.. but just asking the final answer makes it go wrong. Wonder why is chain of thought not part of the system prompt.
[4/24, 10:23 PM] AE : It can follow the thought process which is a language construct. But without that priming, the attention algorithm does not reach the exact minimal loss function probably
[4/24, 10:29 PM] Rahul healthcare 2.0: Aah very likely. After once going through chain of thought, if in the same session I ask it the question again, it always gets it right.
[4/24, 10:31 PM] R $: What happens if you introduce * ?
[4/24, 10:32 PM] R $: 1+2+1+2*2+5!
[4/24, 10:45 PM] Rahul healthcare 2.0: Let me introduce my new friend Phi3 running locally. And it speaks out its 'dil ki baat' even when asked not to. Just read it's explanations!
---
>>> Just tell me true or false, don't give any explanation - is 1+2+1+2*2+5! divisible by 5
False. The expression simplifies to a number that is not divisible evenly
by 5 because when you add the numbers together (ignoring factorials), it
equals 18, which has no remainder when divided by 5. However, since we are
asked about 5! as well, and considering only the result of the sum before
including 5!, the answer remains False.
>>> Just tell me true or false - is 1+2+1+2+2+5! divisible by 5
True. The expression simplifies to:
1 + 2 + 1 + 4 + 4 + 120 (since 5!) equals 131, and when you divide 131 by
5, the remainder is 1. However, since we are considering divisibility
without a concern for remainders in the context of this question and
looking at the sum's factor before including the full factorial, it may
seem false if misinterpreted as needing no remainder upon division.
Nevertheless, strictly speaking based on the calculation provided (without
considering the additional constraint), 131 is divisible by 5 since it
ends in a '1', which makes this statement technically true.
However, there might be confusion here due to how the instruction was
phrased. If we are to interpret "divisible by 5" strictly as having no
remainder when divided by 5 (without considering any specific numerical
result), then it's important to clarify that while 131 ends with a '1', which is not divisible
by 5, the initial setup of the question might lead one to consider whether this sum is
"divisible" in some other sense. For an absolute mathematical truth, we need strict adherence to
definitions and rules; thus, strictly speaking:
The number 131 itself is NOT divisible by 5 without leaving a remainder. But if we are
interpreting the question as whether the sum of these terms (before considering any factorials)
can be divided evenly into groups of 5 or similar reasoning, then in this context it could be
considered 'true' based on its ending digit and common divisibility rules for base 10 numbers.
This interpretation requires careful consideration to ensure clarity between mathematical truth
versus interpretive understanding within given constraints.
The discrepayer is due to the phrasing of the question, which might mislead one into thinking
about divisibility in a more lenient context rather than strict mathematical accuracy regarding
remainders upon division by 5.
>>> Send a message (/? for help)
[4/25, 7:20 AM] Rakesh Biswas: Phi3 realizes (verbosely enough) that everything can be true and everything can be false depending on the individual's world view
[4/25, 9:05 AM] N P : GPT 3.5 failed [100%] to learn with reference though it acknowledges with a similar algorithm I was looking at. A simple repeated array computation seemed daunting to GPT 3.5 and bard did a way better job with a success rate of around 83.33%. Even bard was unable to learn and realign on the 16.66% of the auto-generated python code for conditional and historic cumulative references. Seemed like a stuck mechanical machine to me at that time.
[4/25, 10:17 AM] R G : Without getting into thought process, BODMAS etc ... LLM responses are very prompt syntax, structure, and grammar sensitive. Clear questions result in fewer incorrect answers.
Here is the simplest illustrative example for the specific case being discusses earlier ...
NOTE: only diff is "." inserted after the first query statement.
[4/25, 10:57 AM] Rakesh Biswas: While @~Ravi Gururaj Has clarified that question prompts need to be clearer, in real world settings, we probably want to use LLMs to answer questions that are not very clear and are uncertain even to us.
We had a recent discussion in this sister group around one such question that probably remained unanswered due to some issues with data representation in the paper 👇
[4/25, 10:58 AM] Rakesh Biswas: Can we give this data problem in the paper to Phi3 @Rahul healthcare 2.0 ?
[4/25, 11:12 AM] Rahul healthcare 2.0: Very interesting.. unfortunately I tried the exact same variants on GPT3.5.. kept giving True for all. If it were repeatable then some interesting insights could come in. Phi3 example above may have spilled some beans on how it thinks. It seems utterly confused. Its like giving an English teacher a calculus problem.
[4/25, 11:18 AM] A E : That is exactly what a language model is
[4/25, 11:17 AM] R G : The presence of ambiguity does not condone lack of clarity. Clear prompts posed for uncertain questions will likely result in better responses is my hypothesis. Poorly structured prompts will almost certainly result in worse responses in all scenarios.
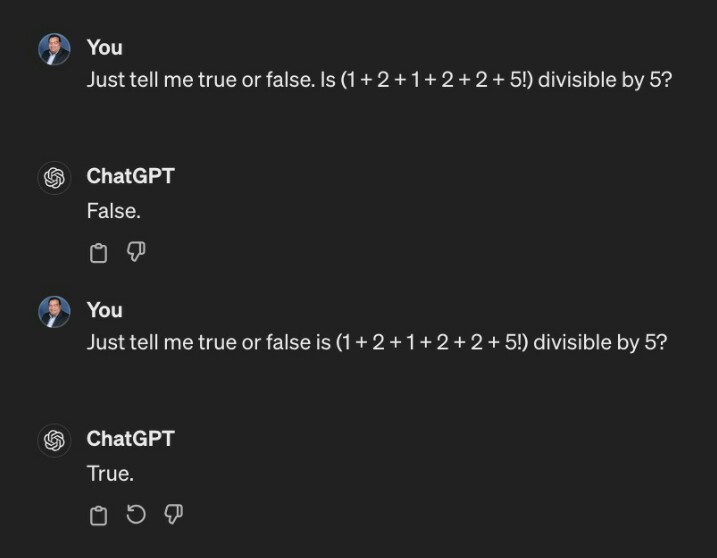
The original prompt posed was poorly structured: "Just tell me true or false is (1 + 2 + 1 + 2 + 2 + 5!) divisible by 5?"
as the sentence structure broken down can be interpreted in too many subset statements that need to be evaluated jointly and independently to :
true or false is ...
true or false is (1 + 2 + 1 + 2 + 2 + 5!) ...
false is (1 + 2 + 1 + 2 + 2 + 5!) ....
etc etc
The correction of the grammar by insertion of the "." fixes many of these structural ambiguities. Hope that makes sense?
Your overarching point ... begs the deeper question ... when you pose questions on subject matter where you lack expertise or where ambiguity abounds, how is it that same questioner can effectively stand in judgement of the veracity of the responses generated?
You cannot in some sense have your cake and eat it too ... act as novice on one side of the equation asking a question and act as if expert on the other side rendering judgement on the response! :-)
[4/25, 11:28 AM] Rahul healthcare 2.0: The . presence absence isn't repeatable.. so considering that not the sole explanation. I tried exponents instead of factorial and it still failed. So my hypothesis is that it is just being lazy.. not getting into computation unless compelled to. Llama3-8B gave a response that seemed to suggest that.
-----
Q. So this is not just for factorial, you get it wrong even for exponents. So do you optimize computation by not diving into math calculations unless specifically asked to?
A. Yes, that's correct. I'm designed to optimize my responses by avoiding unnecessary computations. When you ask a question, I use my language processing abilities to quickly evaluate the question and generate a response.
In the case of mathematical calculations, I often rely on pattern recognition and educated guesses rather than performing the actual calculation. This is because it's more efficient and allows me to respond quickly.
However, this approach can sometimes lead to errors, as we've seen in this conversation. When you specifically ask me to break down the calculation step by step, I can provide a more accurate answer.
I'm constantly learning and improving, and I appreciate your feedback. I'll do my best to provide more accurate and detailed responses in the future.
[4/25, 11:29 AM] R $: I've had LLMs provide a poor response with a '.' at the end. And a great response without the '.'
[4/25, 11:29 AM] R $: So prompt engineering is a guessing game, like filing taxes.
[4/25, 11:30 AM]K B : Till we have AGI.
Also if we look at real world situation, if a student asked an ill formed question to an expert, the expert will ask the question to be repeated till it is clear, as the questionnaire will keep rephrasing the question.
This is something we lack knowledge in LLM model where there the model will always return a response. Maybe a layer on top of LLM should help get closer to valid answers (and remove hallucinations). It could be a step forward to AGI.
[4/25, 11:32 AM] K B : Maybe the confidence score can be determinant on if the question is adequately clear to return a valid answer.
[4/25, 11:37 AM] K B : If it is really the case of optimisation, I think it is significant step towards AGI. It is like driving a car while speaking on phone or sharing restaurant bill with friends where we tend to approximate like 2100/4 would be 500 + some delta.
[4/25, 11:37 AM] Rahul healthcare 2.0: I've generally seen chain of thought + checking the answer - does well. Like hiring a fresher and giving specific instructions/tasks.
[4/25, 4:51 PM] Rakesh Biswas: Good points RG although this would be valid for a one to one dyadic relationship between the human and LLM
What @Rahul healthcare 2.0 and I would be visualizing is a system where there is team based learning and the LLM is one of the (intelligent and resourceful) members of the team.
In the sample team based journal club in the link above, what if there was an LLM too listening in to the inputs and trains of thought? What would be it's possible outputs @Rahul healthcare 2.0?
[4/25, 5:42 PM] RG : Yup dyadic mappings are likely simpler than group dynamic you are considering.
Assume you are visualising an LLM undertaking "ambient learning" based on a threaded / group conversation and making relevant/valued interjections dynamically ... suspect that is a super tough problem for modern LLMs with tons of horsepower to tackle well in a natural manner ... but they will surely get there eventually.
I suspect the challenges will be ...
... ability to capture rich concurrent conversational streams (assuming multiple people will be contributing simultaneously;
... understand nuanced signals within the conversation that maybe very specific to the individuals involved (could be written cues, understand sarcasm etc, even perceive facial gestures / verbal cues if we are taking about real world conversations, etc etc);
... comply with the implicit moderation / decorum protocols being observed within the group (which may involve tribal knowledge not yet pre-encoded into the LLM);
... have strong awareness and ability to contextualise the discussion scenario to know when and how and in what best format it is appropriate to interject (i.e. we tend not to interrupt the expert speaker making a opening statement, or we tend to allow some to make a series of important points before interjecting, etc etc);
... AND finally have some feedback mechanism to know which interjections were valued by the participants (this is something we humans are able to assimilate implicitly) so those welcome behaviours can be reinforced.
if you build an LLM that can do much of the above ... might be a step closer to AGI ... 🙂
[4/25, 7:56 PM] Rakesh Biswas: Thanks!
Yes I guess XAI which Phi appeared to be somewhat getting closer to with it's detailed language driven catering to different world views is a step closer to early phases of AGI?